
Case Studies
The UCREL Semantic Analysis System (USAS)
The UCREL Semantic Analysis System (USAS) is a software system developed to undertake the automatic semantic analysis of text. It has been in use since 1990 when it was developed as part of a project to analyse large bodies of transcribed spoken interviews. Originally developed at the University Centre for Computer Corpus Research on Language, Lancaster University, it has since been used in at least five projects that have involved researchers at Lancaster, most recently in the context of automated semantic assistance for translation between Russian and English (the ASSIST project) and an initiative called Scragg Revisited – a quantitative investigation of spelling across the centuries.
The Project
The original objective of USAS was to construct a system that enables a type of hybrid content analysis using both quantitative and qualitative analysis techniques for text. The specific problem that faced researchers on the ACASD (Automatic Content Analysis of Spoken Discourse) project involved the analysis of large amounts of survey data which had been collected in the form of spoken interviews which were then transcribed. This type of information was difficult to assess statistically and analytically as a coherent body of data and also inhibited the use of that data for subsequent comparative studies.
The development of a comprehensive and granular semantic tagset at the heart of the USAS system was a method of mapping detailed and flexibly structured free text information into a format that facilitated the application of quantitative methods. In combination with additional manual and automated methods of preparation and analysis, including the weighting of words for commonness or rarity with reference to their probable meaning against a general lexicon, USAS proved itself to have both academic and commercial validity and became a useful foundation for further projects such as REVERE – an investigation into documentation relating to business change (1998-2001) - and BENEDICT, which involved the development of a new intelligent dictionary principally focused on the demands of the multi-lingual corporate world (2002-2005).
The latest use of the USAS system involves an additional development of its functionality to enable the analysis of historical texts dating from 1600 onwards. USAS was originally developed to annotate written and spoken English from the modern period but Dawn Archer (university of Central Lancashire) and Paul Rayson (Lancaster University) have implemented a prototype spelling detector as a pre-processing step which is able to identify spelling variants from the sixteenth tothe nineteenth century. Following a time-consuming period of manual matching, the aim is to automate the detection and normalization of spelling variants using 4000 existing examples as benchmarks. The working prototype, VARD, can identify and match variants to their 'normalized' equivalents.
USAS is a tool that has been designed to be used in conjunction with other tools and its longevity and repeated use in the context of projects is a clear indication of its flexibility and its suitability for purpose.
Technical Detail
The USAS category system currently has 21 top-level fields that cover semantic areas such as: General and Abstract Terms; Entertainment Sport and Games; Social Actions State and Processes; etc. and each of these is assigned with a capital letter. This subdivides into 232 category labels which are designated by numbers which then allow for further hierarchically structured mapping of discrete concepts. Antonymity of conceptual classifications can be indicated by +/- markers within the tags (e.g. “A5.1+” = good; “A5.1-“ = bad) and multiple possible semantic domains can be incorporated by use of slash tags (e.g. sportswear may come under the category of both clothing and sport – B5/K5.1).
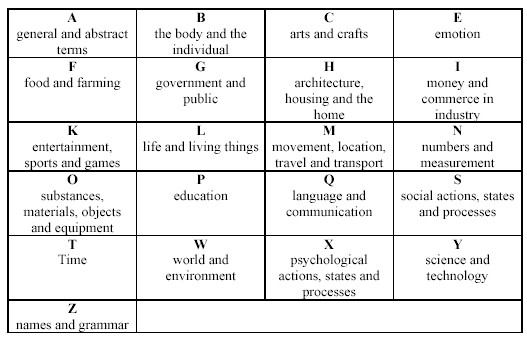
The tagset was loosely based on Tom McArthur's Longman Lexicon of Contemporary English (1981), but was, from the outset, a resource that could be adapted and developed to suit the requirements of the project for which it was being used and the context of the tools that were being used with it. An example of this is the developments that took place during the Benedict project (2002 – 2005) where the tagging tool was re-implemented using Java.
Tools and Methods
Tools
Other tools used in conjunction with the USAS system include the CLAWS tagger which provides an initial identification of parts-of-speech and where appropriate, WMatrix software, which is a web-based tool to extend the functionality of USAS to enable the tagging of key grammatical categories and key semantic fields. This approach has been adopted by Dawn Archer et al in their exploration of ‘Key Domains in Shakespeare’s Comedies and Tragedies’, presented at the Methods Network Expert Seminar on Linguistics,'Word Frequency and Keyword Extraction' (8 September 2005), and demonstrates the value of going beyond standard keyword retrieval to discover those keywords that are related by semantic domain.
Method Categories
Data Analysis; Data Capture; Data Structuring and Enhancement; Communication and Collaboration
Specific Methods
data modelling; markup/text encoding; searching/querying
Project Website
www.comp.lancs.ac.uk/ucrel/usas
Publications/Further Reading
- Rayson, P., Archer, D., Piao, S. L., McEnery, T. (2004). The UCREL semantic analysis system. In proceedings of the workshop on Beyond Named Entity Recognition Semantic labelling for NLP tasks in association with 4th International Conference on Language Resources and Evaluation (LREC 2004), 25th May 2004, Lisbon, Portugal, pp. 7-12.
- Archer, D., Rayson, P., Piao, S., McEnery, T. (2004). Comparing the UCREL Semantic Annotation Scheme with Lexicographical Taxonomies. In Williams G. and Vessier S. (eds.) Proceedings of the 11th EURALEX (European Association for Lexicography) International Congress (Euralex 2004), Lorient, France, 6-10 July 2004. Université de Bretagne Sud. Volume III, pp. 817-827.
- Sawyer, P., Rayson, P. and Cosh, K. (2005) Shallow Knowledge as an Aid to Deep Understanding in Early Phase Requirements Engineering. IEEE Transactions on Software Engineering. Volume 31, number 11, November, 2005, pp. 969 - 981.
- Sampaio, A., Rashid, A., Chitchyan, R. and Rayson, P. (forthcoming) EA-Miner: Towards Automation in Aspect-Oriented Requirements Engineering. Transactions on Aspect-Oriented Software Development (TAOSD) Special issue on Early Aspects, Springer.
Staff and Advisors
Principal Staff
- Dr Dawn Archer, University of Central Lancaster.
- Dr Paul Rayson, Lancaster University.
AHDS Methods Taxonomy Terms
This item has been catalogued using a discipline and methods taxonomy. Learn more here.
Disciplines
- Linguistics
Methods
- Data Analysis - Searching/querying
- Data Structuring and enhancement - Markup/text encoding - descriptive - conceptual
- Data Structuring and enhancement - Markup/text encoding - descriptive - document structure
- Data Structuring and enhancement - Markup/text encoding - descriptive - linguistic structure
- Data Structuring and enhancement - Markup/text encoding - descriptive - nominal
- Data Structuring and enhancement - Markup/text encoding - presentational
- Data Structuring and enhancement - Markup/text encoding - referential